

大型語言模型 (large language model; LLM) 的規模和複雜性日益增加,NVIDIA 今日宣布推出 NeMo Megatron 框架的更新內容,更新後可加快訓練速度達 30%。這些更新內容包括兩項開創性技術及一項超參數工具,用在任意 GPU 數量的 LLM 訓練最佳化及擴展,為使用 NVIDIA AI 平台訓練與部署模型提供新的功能。
全球最大的開放科學、開放取用的多語言模型 BLOOM,內有 1,760 億個參數,日前在 NVIDIA AI 平台進行訓練,能夠產出 46 個語言及 13 種程式語言的文字。NVIDIA AI 平台亦支援其中一個擁有 5,300 億個參數的強大 Transformer 語言模型,即 Megatron-Turing NLG 模型 (MT-NLG)。
在 LLM 領域的最新進展
LLM 是當今最重要的先進技術之一,模型內有數兆個參數,可以從文字中進行學習。但開發 LLM 是個昂貴且耗時的過程,須運用深厚的技術能力、分散式基礎設施與完整堆疊才得以完成。
LLM 在推動即時生成內容、文字摘要、客服聊天機器人與透過對話式人工智慧 (AI) 介面的問答等領域,卻能帶來莫大的好處。為了推動 LLM 的發展,AI 領域的開發人員不斷運用包含 Megatron-LM、Apex 與其他 GPU 加速函式庫的NVIDIA AI 平台來創新開發工具,像是微軟 DeepSpeed、Colossal-AI、Hugging Face BigScience 及 Fairscale。
在 NVIDIA AI 平台推出新的最佳化內容後,能解決整個堆疊中現有的多項痛點。NVIDIA 期待持續與AI 社群合作,讓每個人都能運用 LLM 的強大實力。
縮短 LLM 開發時間
最新的 NeMo Megatron 更新內容可加快 30% 的 GPT-3 模型訓練速度,模型從 220 億個參數,大至 1 兆個參數都可順利運行。現在使用 1,024 個 NVIDIA A100 GPU,只要 24 天就能訓練出多達 1,750 億個參數的模型,相較於過往版本,訓練時間縮短 10 天,相當於約 25 萬個 GPU 運算小時。
NeMo Megatron 是一個快速、高效且易用的端到端容器化框架,用於收集資料、訓練大型模型、按照業界標準基準評估模型,與以最先進的延遲與傳輸量表現進行推論。
使用 NeMo Megatron,便能在多種 GPU 叢集配置上輕鬆處理並複製 LLM 的訓練和推論作業。目前搶先體驗的客戶可以取得這些功能,在 NVIDIA DGX SuperPODs、NVIDIA DGX Foundry 及 Microsoft Azure 雲端環境中運行,並且即將開放支援其他雲端平台。
目前已開放在 NVIDIA LaunchPad 上體驗這些功能。NVIDIA LaunchPad 是一項免費的計畫,提供使用者短期內使用 NVIDIA 加速基礎設施中的多個實作實驗室。
NeMo Megatron 是 NeMo 的一部分。NeMo 是用於為對話式 AI、語音 AI 和生物學打造高效能與靈活應用程式的開源框架。
兩項新技術可加快LLM 的訓練速度
更新項目包括兩項用於最佳化及擴展 LLM 訓練的新技術,即序列平行 (sequence parallelism; SP) 與選擇性激發再運算 (selective activation recomputation; SAR)。
藉由察覺先前未進行平行化的 transformer 層區域在序列維度上是各自獨立,序列平行擴大了 tensor 級模型的平行性。
沿著序列維度拆分這些層就能進行分散運算,而最重要的是,這些區域的激發記憶體分布於 tensor 平行裝置上。由於以分散方式加以激發,可將更多激發作用保留用於反向運算,而不用重新運算。
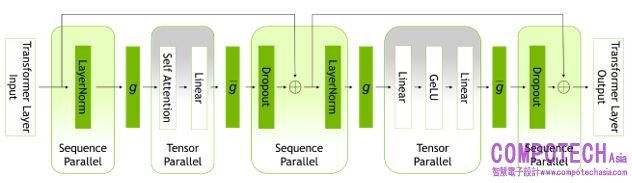
圖一_transformer 層內的平行模式
不同的激發作用需要不同的操作次數來重新運算,選擇性激發再運算改善因記憶體限制而部分被迫重新運算,而非全部激發的情況。除了增加檢查點和重新運算整個 transformer 層,亦可建立檢查點及重新運算每個 transformer 層中,佔用大量記憶體但重新運算的成本不高的部分。
如欲瞭解更多相關資訊,請見《Reducing Activation Recomputation in Large Transformer Models》。
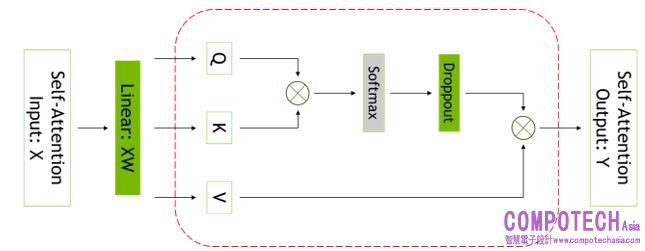
圖二_Self-attention 模塊。紅色虛線代表應用選擇性激發重新運算的區域
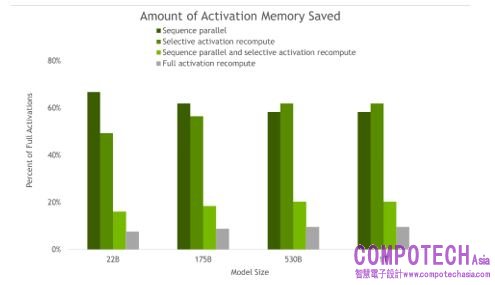
圖三_SP 與 SAR 將激發記憶體保留用於反向運算。隨著模型大小的增加,SP 與 SAR 皆具類似的記憶體保留能力,將所需的記憶體數量減少五倍
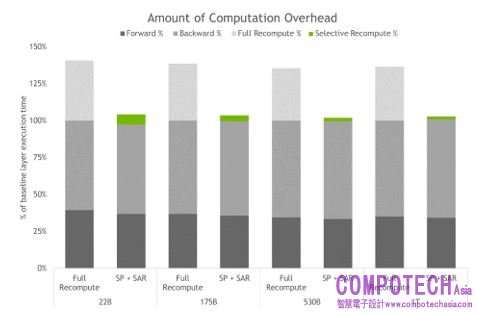
圖四_完全激發再運算與 SP 加上 SAR 的運算時間。長條圖細分出每層的前向、反向和重新運算時間。基線是無採用重新運算和序列平行時的情況。這些技術能在所有激發都被重新運算 (而非保留) 時有效減少額外的運算時間。最大模型的額外時間從 36% 降至僅 2%
要配合高度最佳化的推論策略,才能發揮 LLM 的強大實力。使用者可以輕鬆將訓練好的模型用於推論,並且利用 p-tuning 及 prompt tuning 功能對不同的使用情況進行最佳化調整。
這些功能可以取代微調,讓 LLM 可以適應新的使用情況,無需繁瑣地對完整預先訓練好的模型進行微調。該技術不會更動原始模型裡的參數,便能避免發生因微調模型而出現的災難性「遺忘」問題。欲瞭解更多相關資訊,請見《Adapting P-Tuning to Solve Non-English Downstream Tasks》。
用於訓練和推論的全新超參數工具
在分散式基礎設施中找出適合 LLM 的模型配置非常耗時。NeMo Megatron 推出一項超參數工具,可以自動尋找最佳的訓練和推論配置,且無需修改程式碼。如此一來,LLM 只要一上線便能接受訓練以進行推論收斂,不用浪費時間去尋找高效的模型配置。
NeMo Megatron 使用啟發式方法和經驗網格,在不同參數之間尋找有著最佳傳輸量的配置:資料平行、tensor 平行、流程平行、序列平行、微批次大小與激發檢查點層的數量 (包括選擇性激發重新運算)。
在 NGC 的容器上使用超參數工具與 NVIDIA 測試,在不到 24 小時內便替一個有著 175B GPT-3 模型達到最佳訓練配置 (請見圖五)。與使用完全激發重新運算的一般配置相比,傳輸量速度提高 20% 到 30%。使用最新技術,讓具有超過 20B 參數的模型速度可再加快 10% 到 20%。
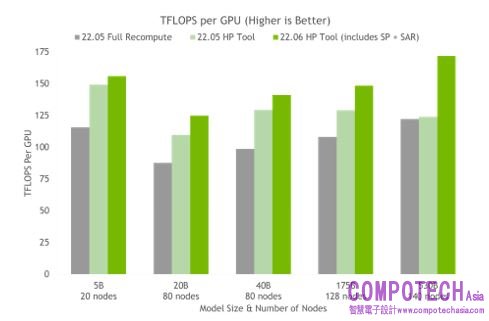
圖五_將超參數工具用於多個容器上的結果顯示,使用序列平行和選擇性激發重新運算,有助於加快處理速度,其中每個節點皆搭載 NVIDIA DGX A100
超參數工具亦能找出推論過程中,有著最高傳輸量或最低延遲的模型配置。模型可以獲得延遲和傳輸量限制資訊,而該工具將會推薦合適的配置。
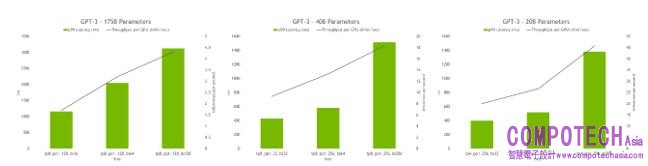
圖六_超參數工具的推論結果顯示每個 GPU 的傳輸量及不同配置的延遲情況。最佳配置包括高傳輸量及低延遲
欲瞭解更多關於適用於 LLM 的 NVIDIA AI 平台最新更新內容,敬請申請搶先體驗 NeMo Megatron。企業亦能在 NVIDIA LaunchPad 上免費體驗 NeMo Megatron。






